
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 페이코 친구코드
- 한정 분기
- php 프로그래밍
- JAVA SPRING
- php 프로그래밍 입문 3판
- 파이썬
- C언어
- Java
- 최단 경로
- php 프로그래밍 입문 연습문제
- php 프로그래밍 입문 솔루션
- 스프링
- php 프로그래밍 입문 예제
- 배열
- 백준
- C
- spring
- php 프로그래밍 입문 문제풀이
- php
- 플러터
- 페이코 초대코드
- 페이코 추천인
- 페이코 추천인코드
- SWEA
- 자바
- 플러터 개발환경 설정
- php 프로그래밍 입문
- Flutter
- programmers
- 자바 스프링
- Today
- Total
ImJay
[파이썬/Python] 최소 비용 신장 트리 알고리즘 구현하기 ( Prim / Kruskal ) 본문
최소 비용 신장 트리 알고리즘 구현하기
서론
신장 트리(Spanning tree)란 연결된 비방향성 그래프에서, 노드는 그대로 유지한 채로, 순환경로(cycle)가 없어지도록 이음선을 제거하여 구성한 연결된 부분그래프입니다.
최소 신장 트리(Minimum spanning tree, MST)는 주어진 그래프의 부분 그래프인 여러 신장 트리 중에서 모든 간선의 가중치 합이 최소가 되는 신장트리입니다.
신장 트리의 의미와 최소 신장 트리를 구하는 두 가지 알고리즘인 프림 알고리즘(Prim algorithm)과 크루스칼 알고리즘(Kruskal algorithm)에 대해 코드를 통해 이해해보도록 하겠습니다.
본론
minimum_spanning_tree.py
import sys
class Graph:
def __init__(self, adjacency_list, directed=False):
self.adjacency_list = adjacency_list
self.nodes = set()
self.edges = set()
self.num_nodes = 0
self.num_edges = 0
if directed:
for node in adjacency_list:
for adjacency_node in adjacency_list[node]:
weight = adjacency_list[node][adjacency_node]
self._add_node_and_edge(node, adjacency_node, weight)
else:
for node in adjacency_list:
for adjacency_node in adjacency_list[node]:
edge_exist_conditions = [
(node, adjacency_node, adjacency_list[node][adjacency_node]) in self.edges,
(adjacency_node, node, adjacency_list[adjacency_node][node]) in self.edges,
] # 1, 2, list[1][2] -> 2, 1
if any(edge_exist_conditions):
assert adjacency_list[node][adjacency_node] == adjacency_list[adjacency_node][node]
else:
weight = adjacency_list[node][adjacency_node]
self._add_node_and_edge(node, adjacency_node, weight)
def _add_node_and_edge(self, s, d, weight):
if s not in self.nodes:
self.nodes.add(s)
self.num_nodes += 1
if d not in self.nodes:
self.nodes.add(d)
self.num_nodes += 1
self.edges.add((s, d, weight))
self.num_edges += 1
class DisjointSet:
def __init__(self, vertices):
self.vertices = vertices
self.parent = {}
self.rank = {}
def make_set(self):
for v in self.vertices:
self.parent[v] = v
self.rank[v] = 0
def find_set(self, item):
if self.parent[item] != item:
self.parent[item] = self.find_set(self.parent[item])
return self.parent[item]
def union(self, x, y):
xroot = self.find_set(x)
yroot = self.find_set(y)
# 랭크가 낮은 집합을 랭크가 높은 집합에 붙임
if self.rank[xroot] > self.rank[yroot]:
self.parent[yroot] = xroot
else:
self.parent[xroot] = yroot
# 랭크가 동일할 때는 붙임을 받은 노드의 랭크 1 증가
if self.rank[xroot] == self.rank[yroot]:
self.rank[yroot] = self.rank[yroot] + 1
class SpanningTree:
def __init__(self, graph):
self.graph = graph
self.prim_tree = {}
self.kruskal_tree = []
def print_solution(self, algorithm=None):
if algorithm == "prim":
print("*** Prim Solution ***")
for v, u in self.prim_tree.items():
print("{0} - {1}".format(u, v))
elif algorithm == "kruskal":
print("*** Kruskal Solution ***")
for u, v in self.kruskal_tree:
print("{0} - {1}".format(u, v))
else:
raise ValueError()
def prim(self, start_node='1'):
S = set()
d = {}
for node in self.graph.nodes:
d[node] = sys.maxsize
d[start_node] = 0
while len(S) != len(self.graph.nodes):
V_minus_S = self.graph.nodes - S
node = self.extract_min(V_minus_S, d)
S.add(node) # 트리 내부 노드 집합에 최소 가중치 노드 추가
if(node==None): break
for adj_node in graph.adjacency_list[node]: # 간선들에 대해
if adj_node in V_minus_S and graph.adjacency_list[node][adj_node] < d[adj_node] :
d[adj_node] = graph.adjacency_list[node][adj_node] # 가중치 저장
self.prim_tree[adj_node] = node # 트리에 정점 저장
def extract_min(self, V_minus_S, d):
min = sys.maxsize
selected_node = None
for node in V_minus_S: # 트리 외부 노드들을 비교
if d[node] < min :# d 값이 가장 작다면
min = d[node] # d 값으로 저장
selected_node = node # 최소 가중치 간선 노드
return selected_node
def kruskal(self):
ds = DisjointSet(self.graph.nodes)
ds.make_set()
i = 0
e = 0
sorted_edges = sorted(self.graph.edges, key=lambda edge: edge[2])
while e < self.graph.num_nodes - 1:
i = sorted_edges.pop(0) # 최소 가중치 간선 꺼내기
u, v = i[0], i[1] # 정점과 그 인접 정점을 저장
if ds.find_set(u) != ds.find_set(v): # 정점 u, v가 다른 집합에 속함
self.kruskal_tree.append((u, v)) # 트리에 추가
ds.union(u,v) # 두 집합을 하나로 합친다
e += 1 # edge count
if __name__ == "__main__":
adjacency_list = {
'1': {'2': 8, '3': 9, '4': 11},
'2': {'1': 8, '5': 14},
'3': {'1': 9, '4': 13, '5': 5, '6': 12},
'4': {'1': 11, '3': 13, '6': 9, '7': 8},
'5': {'2': 14, '3': 5},
'6': {'3': 12, '4': 9, '7': 7},
'7': {'4': 8, '6': 7}
}
graph = Graph(adjacency_list=adjacency_list)
print("[Graph] number of nodes: {0}, number of edges: {1}".format(graph.num_nodes, graph.num_edges))
print(graph.edges)
st = SpanningTree(graph=graph)
st.prim(start_node='1')
st.print_solution(algorithm="prim")
st.kruskal()
st.print_solution(algorithm="kruskal")
Graph Class
import sys
class Graph:
def __init__(self, adjacency_list, directed=False):
self.adjacency_list = adjacency_list
self.nodes = set()
self.edges = set()
self.num_nodes = 0
self.num_edges = 0
if directed:
for node in adjacency_list:
for adjacency_node in adjacency_list[node]:
weight = adjacency_list[node][adjacency_node]
self._add_node_and_edge(node, adjacency_node, weight)
else:
for node in adjacency_list:
for adjacency_node in adjacency_list[node]:
edge_exist_conditions = [
(node, adjacency_node, adjacency_list[node][adjacency_node]) in self.edges,
(adjacency_node, node, adjacency_list[adjacency_node][node]) in self.edges,
]
if any(edge_exist_conditions):
assert adjacency_list[node][adjacency_node] == adjacency_list[adjacency_node][node]
else:
weight = adjacency_list[node][adjacency_node]
self._add_node_and_edge(node, adjacency_node, weight)
def _add_node_and_edge(self, s, d, weight):
if s not in self.nodes:
self.nodes.add(s)
self.num_nodes += 1
if d not in self.nodes:
self.nodes.add(d)
self.num_nodes += 1
self.edges.add((s, d, weight))
self.num_edges += 1
Graph Class 입니다. main 으로부터 받아온 list 를 graph 형태로 변환 시켜주기 위해 필요한 클래스입니다.
Graph Class __init__:
def __init__(self, adjacency_list, directed=False):
self.adjacency_list = adjacency_list
self.nodes = set()
self.edges = set()
self.num_nodes = 0
self.num_edges = 0Graph 클래스의 생성자입니다.
directed는 노드와 인접노드가 연결되어 있는지 확인하는 부울 값입니다.
adjacency_list 는 주어진 그래프를 받아줍니다.
nodes, edges 는 adjacency_list 의 노드와 엣지를 집합의 형태로 받아줍니다.
num_nodes, num_edges 는 노드와 엣지의 수를 선언합니다.
set()
self.nodes = set()
self.edges = set()python에서 set 함수는 집합의 선언을 의미합니다.
- 중복된 값은 자동으로 중복이 제거 됩니다.
- set(집합)은 순서가 없습니다. 어떤 값이 먼저 나올지 알 수 없습니다.
if directed:
for node in adjacency_list:
for adjacency_node in adjacency_list[node]:
weight = adjacency_list[node][adjacency_node]
self._add_node_and_edge(node, adjacency_node, weight)노드와 인접노드가 연결되어 있다면, ( directed == True )
for문을 통해 weight 에 가중치를 저장하고,
본인 노드와 인접노드, weight 를 매개변수로 _add_node_and_edge 함수를 호출해줍니다.
else:
for node in adjacency_list:
for adjacency_node in adjacency_list[node]:
edge_exist_conditions = [
(node, adjacency_node, adjacency_list[node][adjacency_node]) in self.edges,
(adjacency_node, node, adjacency_list[adjacency_node][node]) in self.edges,
]
if any(edge_exist_conditions):
assert adjacency_list[node][adjacency_node] == adjacency_list[adjacency_node][node]
else:
weight = adjacency_list[node][adjacency_node]
self._add_node_and_edge(node, adjacency_node, weight)노드가 인접노드와 연결되어 있지 않다면, ( directed == False )
in 함수를 통해 그래프의 본인 노드와 인접노드가 연결되어 있는지 확인하여 edge_exist_conditions 에 저장합니다.
=> 여기서, 만약 1 - 3 노드가 연결되어 있다면 리스트에는 1 - 3 , 3 - 1 이 동시에 저장되어 있지만,
1 - 3 으로 한번 edge에 저장되면 edge_exist_conditions 에 True 가 반환되기 때문에 3 - 1 이 중복되어 저장되지 않습니다.
any 함수를 통해 연결되어 있다면 assert 문을 통해 한번 더 검증합니다.
연결되어 있지 않다면, weight에 가중치를 저장하고,
본인 노드와 인접노드, weight 를 매개변수로 _add_node_and_edge 함수를 호출해줍니다.
in(set)
>>> 2 in r
True
>>> 3 in r
Falsein 메서드는 집합에 원소가 존재하면 True, 존재하지 않으면 False를 반환합니다.
any()
>>> any([False, False, False])
False
>>> any([False, True, False])
Trueany() 함수는 주어진 값들 중에 하나라도 True가 존재하면 True를 반환합니다. OR과 비슷합니다.
assert
a = 1
>>> assert a == 1
>>> assert a == 2
AssertionErrorassert는 조건이 True인 것을 확인하기 위해 사용합니다.
False는 개발자가 생각하지 않은 동작이므로, 만약 False를 반환한다면 AssertionError를 발생하라는 의미입니다.
Graph Class _add_node_and_edge function:
def _add_node_and_edge(self, s, d, weight):
if s not in self.nodes:
self.nodes.add(s)
self.num_nodes += 1
if d not in self.nodes:
self.nodes.add(d)
self.num_nodes += 1
self.edges.add((s, d, weight))
self.num_edges += 1Graph 클래스에서 집합에 노드와 간선을 추가해주는 역할을 하는 함수입니다.
s = node, d = adjacency_node, weight = weight 입니다.
본인 노드가 노드 집합에 존재하지 않을 경우, 노드 집합에 추가하고 노드 갯수를 카운트 해줍니다.
인접 노드가 노드 집합에 존재하지 않을 경우, 노드 집합에 추가하고 노드 갯수를 카운트 해줍니다.
본인 노드와 인접 노드, 가중치를 하나의 튜플로 간선 집합에 추가하고, 간선 갯수를 카운트 해줍니다.
DisjointSet Class
class DisjointSet:
def __init__(self, vertices):
self.vertices = vertices
self.parent = {}
self.rank = {}
def make_set(self):
for v in self.vertices:
self.parent[v] = v
self.rank[v] = 0
def find_set(self, item):
if self.parent[item] != item:
self.parent[item] = self.find_set(self.parent[item])
return self.parent[item]
def union(self, x, y):
xroot = self.find_set(x)
yroot = self.find_set(y)
# 랭크가 낮은 집합을 랭크가 높은 집합에 붙임
if self.rank[xroot] > self.rank[yroot]:
self.parent[yroot] = xroot
else:
self.parent[xroot] = yroot
# 랭크가 동일할 때는 붙임을 받은 노드의 랭크 1 증가
if self.rank[xroot] == self.rank[yroot]:
self.rank[yroot] = self.rank[yroot] + 1Disjoint Set(서로소 집합, 분리 집합)이란 서로 공통된 원소를 가지고 있지 않은 두 개 이상의 집합을 말합니다. 모든 집합들 사이에 공통된 원소가 존재하지 않는다는 것을, 각 원소들은 하나의 집합에만 속함을 의미하므로, 모든 원소들은 자신이 속해있는 유일한 집합만을 가지게 됩니다.
Disjoint Class __init__:
def __init__(self, vertices):
self.vertices = vertices
self.parent = {}
self.rank = {}Disjoint 클래스의 생성자입니다.
정점과 부모 노드, 정점의 랭크를 생성합니다.
Disjoint Class make_set function:
def make_set(self):
for v in self.vertices:
self.parent[v] = v
self.rank[v] = 0
정점의 부모와 랭크를 설정하는 make_set 함수입니다.
부모를 자기 자신으로 설정합니다.
Disjoint Class find_set function:
def find_set(self, item):
if self.parent[item] != item:
self.parent[item] = self.find_set(self.parent[item])
return self.parent[item]
item 노드가 속한 트리의 루트 노드를 리턴하는 find_set 함수입니다.
부모 노드 포인터를 계속 따라가면서, 포인터 노드 자신을 가리키면 그 노드를 리턴하는 기존 find_set과는 다르게
만나는 모든 노드가 직접 루트를 가리키록 포인터를 변경하여 경로의 길이를 줄이는 작업을 추가하였습니다.
Disjoint Class union function:
def union(self, x, y):
xroot = self.find_set(x)
yroot = self.find_set(y)
# 랭크가 낮은 집합을 랭크가 높은 집합에 붙임
if self.rank[xroot] > self.rank[yroot]:
self.parent[yroot] = xroot
else:
self.parent[xroot] = yroot
# 랭크가 동일할 때는 붙임을 받은 노드의 랭크 1 증가
if self.rank[xroot] == self.rank[yroot]:
self.rank[yroot] = self.rank[yroot] + 1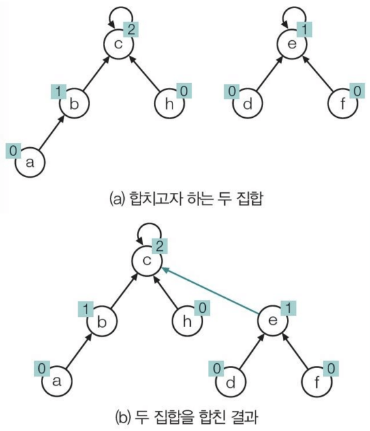
랭크를 이용하여 두 개의 집합을 합치는 union 함수입니다.
랭크는 자신을 루트로 하는 서브 트리의 높이입니다.
각 노드마다 랭크 값을 유지하여 효율적으로(트리의 높이를 낮게) 집합을 합칠 수 있습니다.
find_set 함수를 통해 찾은 각 부모노드를 통해, 랭크가 낮은 집합을 랭크가 높은 집합에 붙입니다.
랭크가 동일한 경우에는 붙임을 받는 노드의 랭크를 1 증가시켜 집합을 합하였습니다.
SpanningTree Class
class SpanningTree:
def __init__(self, graph):
self.graph = graph
self.prim_tree = {}
self.kruskal_tree = []
def print_solution(self, algorithm=None):
if algorithm == "prim":
print("*** Prim Solution ***")
for v, u in self.prim_tree.items():
print("{0} - {1}".format(u, v))
elif algorithm == "kruskal":
print("*** Kruskal Solution ***")
for u, v in self.kruskal_tree:
print("{0} - {1}".format(u, v))
else:
raise ValueError()
def prim(self, start_node='1'):
S = set()
d = {}
for node in self.graph.nodes:
d[node] = sys.maxsize
d[start_node] = 0
while len(S) != len(self.graph.nodes):
V_minus_S = self.graph.nodes - S
node = self.extract_min(V_minus_S, d)
S.add(node) # 트리 내부 노드 집합에 최소 가중치 노드 추가
if(node==None): break
for adj_node in graph.adjacency_list[node]: # 간선들에 대해
if adj_node in V_minus_S and graph.adjacency_list[node][adj_node] < d[adj_node] :
d[adj_node] = graph.adjacency_list[node][adj_node] # 가중치 저장
self.prim_tree[adj_node] = node # 트리에 정점 저장
def extract_min(self, V_minus_S, d):
min = sys.maxsize
selected_node = None
for node in V_minus_S: # 트리 외부 노드들을 비교
if d[node] < min :# d 값이 가장 작다면
min = d[node] # d 값으로 저장
selected_node = node # 최소 가중치 간선 노드
return selected_node
def kruskal(self):
ds = DisjointSet(self.graph.nodes)
ds.make_set()
i = 0
e = 0
sorted_edges = sorted(self.graph.edges, key=lambda edge: edge[2])
while e < self.graph.num_nodes - 1:
i = sorted_edges.pop(0) # 최소 가중치 간선 꺼내기
u, v = i[0], i[1] # 정점과 그 인접 정점을 저장
if ds.find_set(u) != ds.find_set(v): # 정점 u, v가 다른 집합에 속함
self.kruskal_tree.append((u, v)) # 트리에 추가
ds.union(u,v) # 두 집합을 하나로 합친다
e += 1 # edge count프림 알고리즘, 크루스칼 알고리즘과 그 출력에 대해 다루고 있습니다.
SpanningTree Class __init__:
def __init__(self, graph):
self.graph = graph
self.prim_tree = {}
self.kruskal_tree = []SpanningTree 클래스의 생성자입니다.
main으로부터 받아온 graph를 저장하고,
prim 알고리즘의 최소 신장트리와 kruskal 알고리즘의 최소 신장트리를 생성합니다.
SpanningTree Class print_solution function:
def print_solution(self, algorithm=None):
if algorithm == "prim":
print("*** Prim Solution ***")
for v, u in self.prim_tree.items():
print("{0} - {1}".format(u, v))
elif algorithm == "kruskal":
print("*** Kruskal Solution ***")
for u, v in self.kruskal_tree:
print("{0} - {1}".format(u, v))
else:
raise ValueError()SpanningTree 클래스의 출력입니다.
prim 알고리즘과 kruskal 알고리즘을 통해 저장된 그래프를 출력합니다.
format
>>> print("{0} - {1}".format(u, v))
u - v{} 를 활용하여 데이터의 종류에 상관없이 print문으로 표현이 가능합니다.
{}안에 숫자를 입력하여 몇 번째에 오는 데이터를 받을지를 결정합니다.
raise
>>> raise ValueError()
ValueError:예외처리를 위해 사용합니다.
의도치 않은 결과가 나오는 것을 방지하기 위해, 의도하지 않은 조건이 나왔을 경우 raise를 통해 error를 출력합니다.
SpanningTree Class prim function:
def prim(self, start_node='1'):
S = set()
d = {}
for node in self.graph.nodes:
d[node] = sys.maxsize
d[start_node] = 0
while len(S) != len(self.graph.nodes):
V_minus_S = self.graph.nodes - S
node = self.extract_min(V_minus_S, d)
S.add(node) # 트리 내부 노드 집합에 최소 가중치 노드 추가
if(node==None): break
for adj_node in graph.adjacency_list[node]: # 간선들에 대해
if adj_node in V_minus_S and graph.adjacency_list[node][adj_node] < d[adj_node] :
d[adj_node] = graph.adjacency_list[node][adj_node] # 가중치 저장
self.prim_tree[adj_node] = node # 트리에 정점 저장prim 알고리즘을 구현합니다.
def prim(self, start_node='1'):
S = set()
d = {}
for node in self.graph.nodes:
d[node] = sys.maxsize
d[start_node] = 0
트리 내부 노드 집합 S를 선언합니다.
d[node]는 노드와 가장 가까운 S에 속한 정점을 잇는 간선의 가중치 노드입니다.
초기에는 모든 노드를 무한으로 초기화합니다.
start_node는 시작 정점입니다.
처음 시작 정점의 가중치 노드를 0으로 초기화합니다.
while len(S) != len(self.graph.nodes):
V_minus_S = self.graph.nodes - S
node = self.extract_min(V_minus_S, d)
d[node] = -1 # 이미 들렀던 노드 표시
S.add(node) # 트리 내부 노드 집합에 최소 가중치 노드 추가트리 외부 노드 집합 V_minus_S 를 선언합니다.
트리로 포함되기 위하여 대기하고 있는 노드 집합으로, 모든 정점들에서 S를 빼주면 됩니다.
extract_min 함수를 통해 최소 가중치를 갖는 노드를 node에 저장합니다.
d[node] = -1 로 선언하여 이미 들렀던 노드를 표시해주고,
add 함수를 통해 트리 내부 노드 집합 S에 최소 가중치 노드인 node를 추가해줍니다.
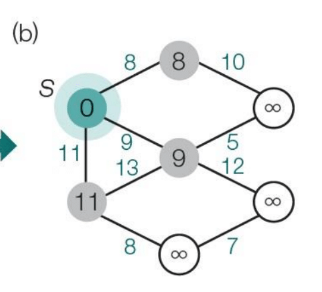
처음 node 값에는 당연하게도, 1이 저장될 것입니다.
왜냐하면 d[start_node=1] = 0 으로 초기화 했기 때문입니다.
for adj_node in graph.adjacency_list[node]: # 간선들에 대해
if adj_node in V_minus_S and graph.adjacency_list[node][adj_node] < d[adj_node] :
d[adj_node] = graph.adjacency_list[node][adj_node] # 가중치 저장
self.prim_tree[adj_node] = node # 트리에 정점 저장최소 가중치 노드를 새롭게 추가하였다면,
우리는 최소 비용 신장 트리를 위해 그 정점의 인접한 정점들의 가중치를 파악해야 합니다.
인접 정점 adj_node 가 트리의 외부 노드 집합이면서, 그 사이 가중치가 기존 저장된 가중치 노드의 가중치 값보다 작다면, 그 인접 정점 adj_node 는 곧 새로운 최소 가중치 노드가 될 것입니다.
조건을 만족하면 d[adj_node] 에 가중치를 저장하고,
prim_tree[adj_node] 에 node 를 저장하여 새로운 최소 가중치 노드를 추가합니다.
Spanning Tree Class extract_min function:
def extract_min(self, V_minus_S, d):
min = sys.maxsize
selected_node = None
for node in V_minus_S: # 트리 외부 노드들을 비교
if d[node] < min and d[node] != -1: # d 값이 가장 작고 들른 적이 없다면
min = d[node] # d 값으로 저장
selected_node = node # 최소 가중치 간선 노드
return selected_nodeextract_min 함수를 통해 최소 가중치를 갖는 노드를 찾습니다.
최소값을 비교하기 위해 min 에 max 값을 넣어주고,
트리 외부 노드들을 비교하여 가중치 노드 값이 가장 작고, 들른 흔적이 없다면
최솟값으로 저장하고, 최소 가중치 노드로 채택합니다.

node = 1 의 인접 노드인 adj_node = 2, 3, 4이고, weight는 각각 8, 9, 11 입니다.
해당 값들이 d[adj_node] 에 저장된 후에, 다음 루프에서 extract_min function 이 호출되면, 가중치가 가장 작은(weight = 8) adj_node = 2가 selected_node 가 될 것입니다.
Spanning Tree Class kruskal function:
def kruskal(self):
ds = DisjointSet(self.graph.nodes)
ds.make_set()
i = 0
e = 0
sorted_edges = sorted(self.graph.edges, key=lambda edge: edge[2])
while e < self.graph.num_nodes - 1:
i = sorted_edges.pop(0) # 최소 가중치 간선 꺼내기
u, v = i[0], i[1] # 정점과 그 인접 정점을 저장
if ds.find_set(u) != ds.find_set(v): # 정점 u, v가 다른 집합에 속함
self.kruskal_tree.append((u, v)) # 트리에 추가
ds.union(u,v) # 두 집합을 하나로 합친다
e += 1 # edge count크루스칼 알고리즘 구현입니다.
def kruskal(self):
ds = DisjointSet(self.graph.nodes)
ds.make_set()
i = 0
e = 0
sorted_edges = sorted(self.graph.edges, key=lambda edge: edge[2])노드를 매개변수로 DisjointSet 클래스를 만들고,
make_set() 함수를 통해 각 정점들의 부모노드와 랭크를 초기화합니다.
모든 간선을 가중치의 크기 순으로 정렬하여 sorted_edges 에 저장합니다.
while e < self.graph.num_nodes - 1:
i = sorted_edges.pop(0) # 최소 가중치 간선 꺼내기
u, v = i[0], i[1] # 정점과 그 인접 정점을 저장
if ds.find_set(u) != ds.find_set(v): # 정점 u, v가 다른 집합에 속함
self.kruskal_tree.append((u, v)) # 트리에 추가
ds.union(u,v) # 두 집합을 하나로 합친다
e += 1 # edge count오름차순으로 가중치를 정렬한 리스트에서 최소 가중치 간선을 꺼내고,
간선 튜플에서 정점과 인접 정점을 저장합니다.
정점 u, v 가 다른 집합에 속할 경우 트리에 추가하고, 두 집합을 하나로 합쳐줍니다.
상호 배타적 집합이 차례로 1개씩 줄어들면서 최종적으로 1개의 트리로 구성이 됩니다.

__main__:
if __name__ == "__main__":
adjacency_list = {
'1': {'2': 8, '3': 9, '4': 11},
'2': {'1': 8, '5': 14},
'3': {'1': 9, '4': 13, '5': 5, '6': 12},
'4': {'1': 11, '3': 13, '6': 9, '7': 8},
'5': {'2': 14, '3': 5},
'6': {'3': 12, '4': 9, '7': 7},
'7': {'4': 8, '6': 7}
}
graph = Graph(adjacency_list=adjacency_list)
print("[Graph] number of nodes: {0}, number of edges: {1}".format(graph.num_nodes, graph.num_edges))
print(graph.edges)
st = SpanningTree(graph=graph)
st.prim(start_node='1')
st.print_solution(algorithm="prim")
st.kruskal()
st.print_solution(algorithm="kruskal")구현 파트입니다.
adjacency_list 는 정점, 인접 정점, 가중치를 차례로 딕셔너리 형태로 저장합니다.
결론

프림 알고리즘과 크루스칼 알고리즘에 따라서 최소 비용 신장 트리가 정상적으로 출력됨을 확인할 수 있습니다.
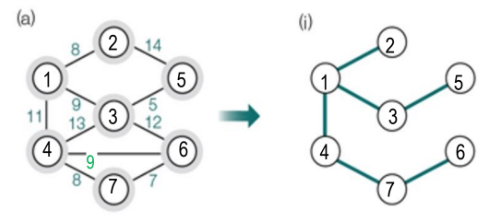
프림 알고리즘과 크루스칼 알고리즘을 구현해보면서, 최소 신장 트리(MST)란 무엇인지 배우고
노드와 간선의 작성 방법과 이를 집합으로 표현하는 방법에 대해 자세히 알 수 있었습니다.
'파이썬' 카테고리의 다른 글
| [파이썬/Python] 최단 경로 알고리즘 작동원리 이해하기 ( Floyd-washall ) (0) | 2022.06.03 |
|---|---|
| [파이썬/Python] 최단 경로 알고리즘 작동원리 이해하기 ( Dijkstra ) (0) | 2022.06.02 |
| [파이썬/Python] 최소 비용 신장 트리 알고리즘 작동원리 이해하기 ( Prim / Kruskal ) (0) | 2022.06.02 |
| [파이썬/Python] 동적 프로그래밍 - 행렬 곱셈 순서 계산하기 ( Brute-Force Algorithm ) (0) | 2022.06.02 |
| [파이썬/Python] 최단 경로 알고리즘 구현하기 ( Dijkstra / Bellman-ford / floyd-warshall ) (0) | 2022.06.01 |



